Abre cualquier informe reciente que hable sobre ITSM, acude a cualquier webinar organizado por algún proveedor de software o lee el último Cuadrante Mágico de Gartner. No tardarás ni cinco minutos en encontrarte con la métrica del terror:
Te lo repiten hasta hartarte. Te lo imprimen en gráficos de barras de colores. Te lo cuentan una y otra vez los comerciales de software antes de pasarte un presupuesto de seis cifras para su nueva herramienta de Inteligencia Artificial "mágica".
Vamos a decir la verdad de una vez: si tu empresa perdiera 100.000 euros por cada hora que se cae un servidor, no estarías leyendo este artículo en LinkedIn. Estarías en tu yate en Ibiza.
A menos que seas tipo Banco Santander, Amazon en medio del Black Friday, o la red de AENA, que se te caiga el CRM quince minutos, que el ERP dé un error 500 o que la pasarela de la intranet no cargue, no te va a llevar a la quiebra. Es una molestia, sí. Es un problema de servicio, por supuesto. Pero no es el apocalipsis financiero que te intentan vender para que compres licencias a precio de oro.
Basta de terrorismo comercial.
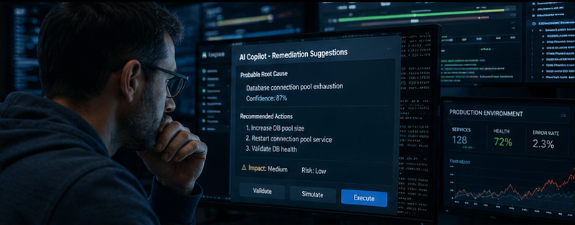
El coste real: silencioso, humano y mensual
El problema real de las incidencias de tecnología no es el minuto de downtime. El sangrado real en las empresas, el que de verdad cuesta dinero todos los meses, es silencioso, no sale en los titulares y tiene forma de nómina y desgaste humano.
de tus desarrolladores e ingenieros gastan al menos la mitad de su jornada laboral apagando fuegos — State of AI-First Operations Report, 2026
Ese es el verdadero coste. No son ventas perdidas por un carrito abandonado; son los sprints de desarrollo que no se entregan, es talento técnico de 60K€ al año haciendo de operador telefónico, y es un equipo de TI quemado, desmotivado y a punto de pedir la baja por ansiedad.
Estamos tomando la resolución de incidencias como si fuéramos un equipo de boxes de la Fórmula 1, pero nos parecemos más a un taller de barrio intentando arreglar un pinchazo con un tenedor.
Si de verdad quieres dejar de quemar dinero y talento, lo primero es dejar de creerte las estadísticas del mercado y empezar a mirar cómo funcionan tus tripas operativas. No recuerdo una empresa, en los casi 25 años que llevo en este sector, que supiera con seguridad cuánto le costaba cada hora de downtime.