Open any recent report about ITSM, attend any webinar organised by a software vendor, or read the latest Gartner Magic Quadrant. It will not take you five minutes to stumble across the terror metric:
They repeat it until you are sick of it. They print it in colourful bar charts. Vendor salespeople tell you over and over before handing you a six-figure quote for their new "magic" Artificial Intelligence tool.
Let us tell the truth for once: if your company were losing €100,000 for every hour a server goes down, you would not be reading this article on LinkedIn. You would be on your yacht in Ibiza.
Unless you are the Santander Bank, Amazon in the middle of Black Friday, or the AENA network, having your CRM down for fifteen minutes, your ERP throwing a 500 error, or the intranet gateway failing to load is not going to bankrupt you. It is an inconvenience, yes. It is a service problem, of course. But it is not the financial apocalypse vendors try to sell you in order to move gold-priced licences.
Enough with the commercial scaremongering.
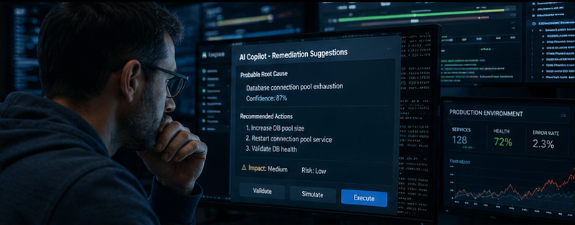
The real cost: silent, human and monthly
The real problem with technology incidents is not the minute of downtime. The true bleeding in companies — the kind that genuinely costs money every month — is silent, does not make headlines, and takes the shape of payroll and human burnout.
of your developers and engineers spend at least half their working day firefighting — State of AI-First Operations Report, 2026
That is the real cost. Not lost sales from an abandoned shopping cart; it is development sprints that are never delivered, it is technical talent earning €60K a year acting as a telephone operator, and it is an IT team burned out, demotivated and on the verge of filing for stress leave.
We are treating incident resolution as if we were a Formula 1 pit crew, but we look more like a neighbourhood garage trying to fix a flat tyre with a fork.
If you truly want to stop burning money and talent, the first step is to stop believing market statistics and start looking at how your operational internals actually work. In nearly 25 years in this industry, I cannot recall a single company that knew with certainty how much each hour of downtime cost them.