Abra qualquer relatório recente sobre ITSM, assista a qualquer webinar organizado por um fornecedor de software ou leia o último Quadrante Mágico do Gartner. Não vai demorar cinco minutos a encontrar a métrica do terror:
Repetem-no até à exaustão. Imprimem-no em gráficos de barras coloridos. Os comerciais de software dizem-no repetidamente antes de lhe apresentar um orçamento de seis dígitos para a sua nova ferramenta de Inteligência Artificial "mágica".
Vamos dizer a verdade de uma vez: se a sua empresa perdesse 100.000 euros por cada hora que um servidor vai abaixo, não estaria a ler este artigo no LinkedIn. Estaria no seu iate em Ibiza.
A menos que seja o Banco Santander, a Amazon no meio da Black Friday, ou a rede da AENA, ter o CRM em baixo quinze minutos, o ERP a dar um erro 500 ou o gateway da intranet a não carregar não o vai levar à falência. É um incómodo, sim. É um problema de serviço, claro. Mas não é o apocalipse financeiro que lhe tentam vender para que compre licenças a preço de ouro.
Chega de terrorismo comercial.
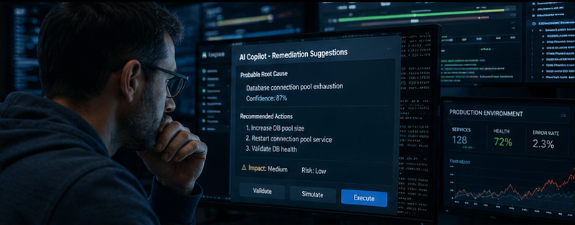
O custo real: silencioso, humano e mensal
O problema real dos incidentes de tecnologia não é o minuto de downtime. A hemorragia real nas empresas — a que verdadeiramente custa dinheiro todos os meses — é silenciosa, não aparece nos títulos dos jornais e tem forma de folha de pagamentos e desgaste humano.
dos seus programadores e engenheiros gastam pelo menos metade do seu dia de trabalho a apagar fogos — State of AI-First Operations Report, 2026
Esse é o custo real. Não são vendas perdidas por um carrinho abandonado; são os sprints de desenvolvimento que não são entregues, é talento técnico de 60K€ por ano a fazer de operador de call center, e é uma equipa de TI esgotada, desmotivada e prestes a pedir baixa por ansiedade.
Estamos a tratar a resolução de incidentes como se fôssemos uma equipa de pit lane de Fórmula 1, mas parecemo-nos mais com uma oficina de bairro a tentar arranjar um furo com um garfo.
Se de facto quer deixar de queimar dinheiro e talento, o primeiro passo é deixar de acreditar nas estatísticas de mercado e começar a olhar para como funcionam as suas entranhas operacionais. Não me recordo de uma única empresa, nos quase 25 anos que levo neste setor, que soubesse com certeza quanto lhe custava cada hora de downtime.